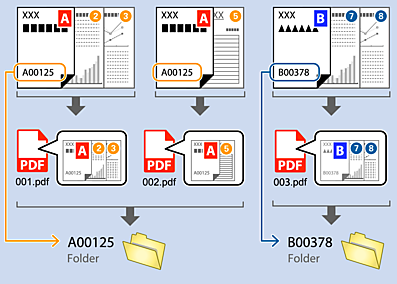
Création et enregistrement de dossiers à l'aide de caractères OCR
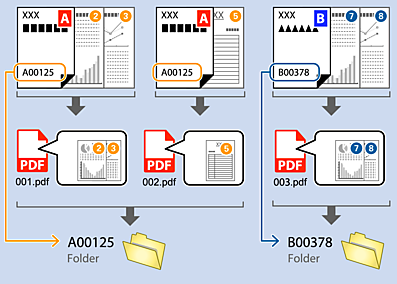
A l'aide de l'OCR (fonction de détection de texte dans des images numérisées et de conversion en texte lisible), vous pouvez séparer des fichiers en utilisant le texte lu dans une zone spécifique, puis créer et enregistrer des dossiers en utilisant le texte ainsi reconnu.
Cette section explique les paramètres de la tâche «Création et enregistrement de dossiers en utilisant le texte lu par OCR».
-
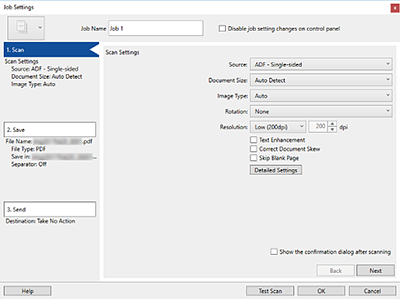
Affichez l'écran Paramètres de travaux.
-
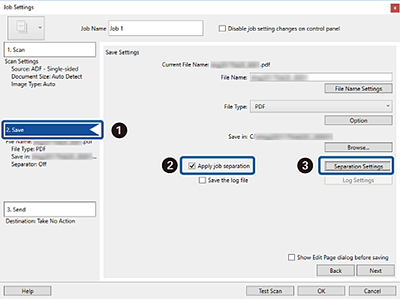
 Cliquez sur l'onglet 2. Enregistrer,
Cliquez sur l'onglet 2. Enregistrer,  sélectionnez Appliquer sép. travaux, puis
sélectionnez Appliquer sép. travaux, puis cliquez sur Par. séparation.
cliquez sur Par. séparation.
-
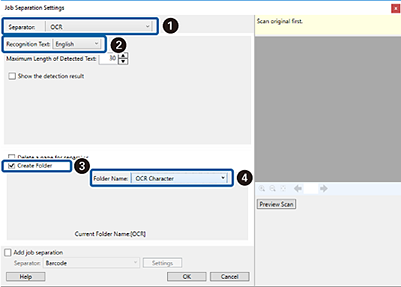
Sur l'écran Paramètres de séparation de travaux,
définissez Séparateur sur OCR, et ensuite sélectionnez la langue du texte en cours de lecture depuis Reconnaissance de texte . Sélectionnez Créer un dossier, puis  définissez Nom de dossier sur Caractère OCR.
définissez Nom de dossier sur Caractère OCR.
-
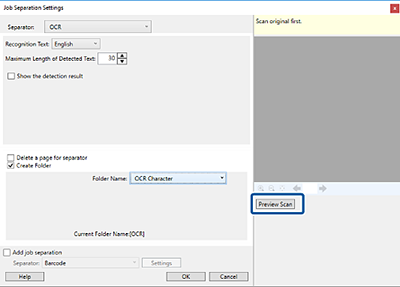
Pour définir la zone de détection de texte OCR, placez le document sur le scanner, cliquez sur Scanner, puis cliquez sur OK sur l'écran Paramètres de scannage.
-
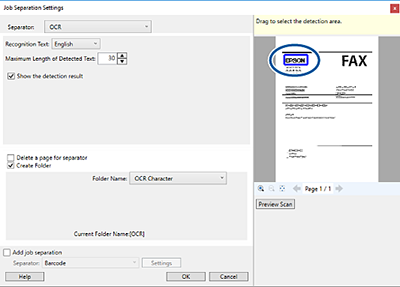
Dans l'image de prévisualisation numérisée, spécifiez la zone de détection de texte. Cliquez sur le point de départ et faites glisser la souris pour afficher un cadre bleu et spécifier la zone de détection du texte.
 Remarque:
Remarque:-
Dans Longueur maximale de texte détecté, Vous pouvez spécifier le nombre maximum de caractères maximum extraits du texte détecté dans la zone spécifiée utilisés pour le nom du dossier.
-
Si vous ne souhaitez pas enregistrer les pages utilisées pour le tri, sélectionnez Supprimer une page comme séparateur. Les pages inutiles sont alors supprimées avant l'enregistrement des données.
-
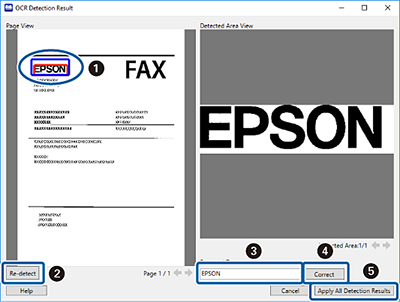
Sélectionnez Afficher les résultats de détection pour vérifier si le texte a été lu correctement ou non. Sur l'écran affiché après la numérisation, vous pouvez vérifier la zone et le texte qui a été reconnu. Vous pouvez également spécifier la zone (
, ), et corriger le texte (, ). Après avoir vérifié toutes les pages,  cliquez sur Appliquer tous les résultats de reconnaissance.
cliquez sur Appliquer tous les résultats de reconnaissance.
-